Cloud Computing: Virtualisierungsschicht – Gastbeitrag von Stefan Rühl
Im ersten Teil seines Gastbeitrages über Cloud Computing beschäftigte sich Stefan Rühl mit der Frage “Was ist Cloud Computing?“. Im zweiten Teil ging es um “Dedicated Hosting oder virtualisierte Lösung?” Der dritte Teil beschäftigte sich mit der Frage “Private managed Cloud – die ideale Lösung?” Im vierten Teil geht es um Virtualisierungsschicht.
Virtualisierungsschicht: Um eine Virtualisierungsumgebung darstellen zu können, wird eine entsprechende Software benötigt. Neben den unzähligen freien Systemen wie XEN, Eucalyptus, Red Hat Enterprise Virtualisierung RHEV, etc. hat sich die kommerzielle Lösung VMware etabliert.
Eine Aussage, dass VMware besser ist oder die kostenfreien Produkte innovativer sind, kann so nicht getroffen werden. Zwar kosten VMware Lizenzen viel Geld, insbesondere wenn es sich um ESX Lizenzen handelt, jedoch steht hier ein entsprechendes Unternehmen dahinter – und somit auch Support.
Wichtig für den Kunden, welcher die Plattform betreiben wird, sind neben dem eigenen Know-how auch die angebotenen SLAs des anbietenden Carriers. Es macht wenig Sinn, sich hohe SLAs auf Serverhardware und Storage geben zu lassen und nur minimale auf die Virtualisierungsschicht. Vielmehr sollten SLAs entweder auf die Verfügbarkeit und Performance der Virtualisierungssoftware oder besser noch auf die Instanzen eingekauft werden. In der „Königsklasse“ werden die Verhandlungen mit dem Carrier auf der Ebene des OS innerhalb der Instanz, bzw. auf die dort laufenden Dienste (Webserver, Datenbank, Mailservices etc.) eingekauft – natürlich mit SLA und Pönalen.
Aber zurück zur Auswahl der Virtualisierungssoftware. Neben den Lizenzkosten und den Services des Carriers ist auch die Kompatibilität zu anderen Plattformen wichtig. Es macht wenig Sinn, auf der eigenen Plattform VMware einzusetzen, wenn die Lastspitzen zu Amazon in eine Elastic Cloud verschoben werden sollen. Dort arbeitet open nebula. Und eine VMware Instanz startet derzeit nicht unter open nebula. Sollte also die E2 für Peaks benutzt werden, empfiehlt sich, die eigene Plattform ebenfalls mit open nebula auszustatten.
Inzwischen setzt sich aber immer mehr der Trend durch, dass Unternehmen, welche aus rechtlichen oder unternehmenspolitischen Gründen eine dedicated Cloud mit VMware betreiben und diese für Peak Belastungen ausgelegt haben, Ihre ungenutzten Ressourcen anderen Unternehmen zur Verfügung stellen. Hier ist es notwendig, ebenfalls VMware einzusetzen, um solche Ressourcen einkaufen und nutzen zu können. Dieses Beispiel zeigt, dass für das richtige Design auch ein weiter Blick in die Zukunft zu richten ist. Einmal das falsche Setup gewählt, und die IT Kosten skalieren nicht mehr in die richtige Richtung.
Cloud aus Sicht des Anbieters
Cloud ist spätestens seit dem erfolgreichen Start von „AmazonS“ und S3 in aller Munde. Keine Veranstaltung im IT Umfeld mehr, ohne dass auf die Cloud-Trommel geschlagen wird. Doch welche Themen sind für Anbieter / Carrier heute wirklich entscheidend?
Schauen wir mal auf die Beweggründe, warum fast alle Kunden, welche Serverplattformen betreiben, Cloud Lösungen – oder nennen wir es lieber dynamische Virtualisierungslösungen – verlangen.
Wie bereits erwähnt haben heutige Plattformbetreiber das Problem, dass zu über 70 % der Zeit 30 bis 50 % der Plattformen nicht genutzt werden. Aufgrund verschiedenster Architekturen gibt es einige Server, welche unter Dauerlast laufen und viele andere warten oft Tage lang, dass mal wieder ein paar User Last erzeugen. Also warum nicht einfach die Plattform auf das Nötigste reduzieren und einen Anbieter suchen, der wenn Last entsteht, in kürzesten Abrechnungszyklen Prozessoren und RAM zur Verfügung stellt. Eben so, wie es Amazon macht. Dazu dann auch einen Storage, der auch in kleinsten Abnahmemengen high IO liefert.
Diese Anforderung ist absolut vernünftig und kaufmännisch auch notwendig.
Warum gibt es dann in Deutschland keinen Anbieter, der eine solche Lösung anbietet?
Nach vielen Gesprächen mit Providern / RZ Betreibern in Deutschland habe ich immer wieder einen Grund gefunden, der am Ende des Gespräches benannt wurde. Es besteht die Angst vor dem Invest bzw. einem Fehlinvest. Einige Unternehmen gehen den Weg, dass Sie erst mal ihren Sales aufstocken und dann mit den ersten gewonnenen Projekten den Einstieg in das Thema Cloud wagen wollen. Dazu besteht dann der Glaube, dass die vorhandenen Techniker das Thema schon mit erledigen… Das Ergebnis sind schlecht laufende Plattformen, Probleme beim Skalieren und im Betrieb. Andere Unternehmen bauen „ein wenig VMware Server auf“ und meinen, dass ist jetzt die Lösung. Was hier fehlt, ist ein umfassendes Konzept und eine qualifizierte Mannschaft.
Anbei soll versucht werden, einen groben Überblick über einen möglichen Lösungsansatz zu geben.
Plattform
Wie bereits erwähnt müssen einige Themen im Vorfeld bedacht werden. Z.B., welche Virtualisierungsform gewählt werden soll. Im folgenden Beispiel werde ich auf VMware setzen, da ich hier einige Vorteile sehe.
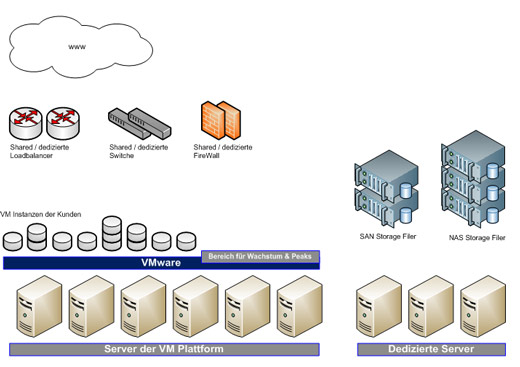
Bei der Auswahl der Hardware sollte natürlich nur auf einen Hersteller gesetzt werden. Das vereinfacht den Betrieb erheblich. Zu beachten ist, dass Stand heute eine VM Instanz nicht über mehrere Server gehen kann. Dieses wird sicherlich irgendwann möglich sein. Besonders wichtig ist dieses Thema, da zu schwach dimensionierte Server so zu klein für manche Instanz sein könnten. Ergo sollten eher leistungsstärkere Maschinen eingesetzt werden. Sinnvoll ist es, die breite Masse mit Blade Servern aufzubauen und daneben auf das zu schauen, was die Kunden benötigen. Betrachten wir das Portfolio z.B. von HP, so sollten neben Blades DL385 und DL585 eingesetzt werden.
Soweit ist das Thema recht einfach. Komplexer wird es mit dem Thema der Peaks. Hier gibt es zwei Ansätze. Um die Kunden schnell beliefern zu können, sollte die Plattform immer ausreichend mit Servern ausgestattet sein. Auf Monatsebene betrachtet sollte immer die durchschnittliche Verkaufsmenge + < 20 % an Hardware im installierten Vorlauf sein. Das entlastet auch die Technik beim Aufbau neuer Hardware und erspart unnötige Eskalationen. Eine Möglichkeit, um das Thema Peaks zu bedienen, wäre es, die Plattform so weit zu überdimensionieren, dass die Kunden dort Ihre Peaks abarbeiten können. Die andere Alternative ist eine zweite Plattform, welche ausschließlich für Peaks zur Verfügung steht. Diese könnte auch mit älterer Hardware bestückt werden. Allerdings verursacht auch dort jeder Server RZ Kosten (Fläche, Strom, Rack…). Wenn man hier die Kalkulationen betrachtet, kommt man schnell zu dem Ergebnis, dass die Variante 1 sich besser rechnet, da die Ressourcen, welche heute für Lastspitzen zur Verfügung stehen, morgen die Server der neuen Kunden sind. Es muss also lediglich vor Vorlauf an verbauter Hardware genau getrackt und nachgeordert werden.
Interessant wird das Thema, wenn der Carrier 2 Rechenzentrumsstandorte sein Eigen nennt und an beiden Lokationen identische Plattformen stehen. So können die Peaks auch in das zweite RZ verschoben werden – vorausgesetzt, die RZs sind entsprechend performant verbunden.
Ein absoluter USP für den Kunden ist es, wenn ein Carrier mehrere solcher RZs in verschiedenen Ländern oder Kontinenten hat. Hier können dann die Stärken von VMware voll ausgespielt werden. Hat der Kunde auf seiner Plattform viel Last aus z.B. Latein Amerika, dann werden eben die entsprechenden Instanzen nach dort verschoben.
Da die Peaks meist nur wenige Minuten dauern braucht der Kunde also auch nur für wenige Minuten zusätzliche Ressourcen. Das ruft ein heute bei den meisten Carriern unterschätztes Thema auf… Billing. Eine der wichtigsten Vorüberlegungen, welche beim Aufbau einer solchen Plattform anzustellen ist, ist die Auswahl des richtigen Billing Systems und eines automatisierten provisioning.
Nur wenn diese beiden Systeme richtig ausgewählt, implementiert und betrieben werden, arbeitet eine solche Plattform effizient. Aber keine Angst, solche Tools können heute gekauft werden. Selber frickeln muss nicht sein. Hier müssen absolut professionelle Werkzeuge eingesetzt werden, welche auch skalieren.
Heute versuchen einige Carrier, Server auf Monatsebene für Peaks bereit zu stellen. Das stellt jedoch eher eine Notlösung dar. Die Kunden erwarten heute eine Abrechnung im Minuten Takt. Sicherlich ist es kein Problem, hier auf Stunden- oder Tageswerte zu gehen, um die Rechnungen noch übersichtlich zu halten. Auch könnte ein 95/5er Modell auf Monatsebene angeboten werden. Bei Bandbreitenabrechnung hat sich dieses Thema schon seit Jahren etabliert. Eine Abrechnung nach Volumen erachte ich als nicht sinnvoll.
Beim Design einer solchen Lösung sind aber noch weitere Themen zu beachten. So gibt es Kunden, welche aus verschiedensten Gründen dedizierte Hardware benötigen. Teils als eigene VM Umgebung, teils als reine Rootserver mit OS. Diese Systeme müssen mit der VM Plattform kommunizieren können. Es gibt diverse Plattformen, welche Ihre BackEnds als klassische dedizierte Serverlösung designt haben und Ihre FrontEnds in virtualisierter Umgebung betreiben. Insbesondere beim Design der Netzwerkinfrastruktur des RZ muss dieser Punkt Beachtung finden.
Loadbalancer
Ohne diese hilfreichen Maschinen geht in einer wachsenden Plattform so gut wie nichts mehr. Hier ist es wichtig, dass der Kunde sowohl als VM Kunde, als auch als Kunde einer dedizierten Lösung sowohl shared als auch dedizierte Geräte zur Verfügung gestellt bekommt. Natürlich sollte auch hier nur auf einen Hersteller gesetzt werden, um eine Kompatibilität über alle Standorte zu haben. Es versteht sich von selbst, dass grundsätzlich nur Pärchen zum Einsatz kommen. Solomaschinen sind etwas für Home Lösungen.
FireWalls & Switche
Hier gilt gleiches wie beim Punkt Loadbalancer.
Beispiel einer möglichen VM Plattform
Welches OS / welche Distribution?
Alle Kundenwünsche zu erfüllen ist schlicht nicht möglich. Ein Basisportfolio ist sicher Windows (+ Enterprise), RedHat (+Enterprise), Debian, Unbuntu, Centos.
Natürlich ist es kostentechnisch nicht akzeptabel, wenn ein Techniker jeden Server / jede Instanz per Hand installieren soll. Hier ist ein Installroboter zu implementieren. Mit jedem Kunden sind in der Projektierungsphase die Designs für die einzelnen Servertypen festzulegen und auf dem Roboter oder dessen Storage abzulegen. Ordert der Kunde später einen DB oder Webserver nach, so muss der Installationsprozess klar geregelt sein (IP bereit stellen, Server in Plattform aktivieren, Eintrag in Loadbalancer, Image ausrollen, Test & Übergabe an Kunden).
Storage
Dem Storage in einer virtualisierten oder auch dedizierten Umgebung muss ebenfalls eine besondere Beachtung geschenkt werden. Leider gibt es nicht DEN richtigen Storage für alle Kundenanforderungen. Im Folgenden sollen die häufigsten und wichtigsten Kundenanforderungen besprochen werden.
Datenbank Storage SAN
Viele Portale haben im Verhältnis zu heutigen Storagegrößen recht kleine Datenbanken. Viele sind weit unter 10/20 GB angesiedelt. Was sie aber alle brauchen, ist eine hohe IO Performance. Manche im Schreib-, andere im Lesemodus. In den seltensten Fällen kommt ein Kunde unter eine IO Anforderung von 5/8.000 IOps. Nicht selten werden Werte im Peak von weit über 20.000 IOps gefordert. Wie bereits zu Beginn dieses Artikels beschrieben, müsste der Kunde viele TerraByte ordern, um diese IO Werte zu erreichen. Leider ist aber kein Kunde bereit, diesen Preis zu bezahlen.
Einige Carrier haben diese Situation erkannt und sich Enterprise Shared Storage Systeme von z.B. NetApp, HDS oder EMC zugelegt. Diese Systeme verfügen meist über > 70 TB und die entsprechenden Ports, um die Leistung auch an die Server ohne Verlust zu transportieren. Als Platten werden 300 oder 500 TB FC Platten mit 15k Umdrehung eingesetzt. Meist werden diese SANs via FibreChannel an die Server angebunden. Wichtig hierbei ist, dass die Shelves mit den Platten nicht als einzelne Aggregate installiert werden, sondern als ein einziges. Getreu der Devise: viele Platten in einem Aggregat = viele IOps. Für jeden Kunden werden LUNs eingerichtet und somit der high performance Storage bereit gestellt. Natürlich muss auch hier erst ein Invest getätigt werden. Jedoch bei dem heutigen Storagebedarf ist so ein System schneller ausgelastet als man denkt. Der dabei erwirtschaftete Ertrag ist i.d.R sehr erfreulich.
NAS Storage
Neben dem HighPerformance DB Storage benötigen die Kunden auch Platz zum Ablegen von Bildern, Videos etc. Hier sollte ebenfalls ein Shared Storage eingesetzt werden. Jedoch können hier neben den schnellen und kleinen FC Platten auch größere STAA Platten verwendet werden, häufig in der Größe von 1TB. Dieser Storage ist dann natürlich kostengünstiger. Sollte ein Kunde auch für seine Daten die high performance Werte des DB Storage benötigen, so spricht nichts dagegen, ihm diesen auch dafür zur Verfügung zu stellen.
Bei beiden Systemen versteht es sich von selbst, dass die Filer mit redundanten Köpfen auszustatten sind und als Cluster designt werden müssen.
Das Billing kann hier sowohl für längere Laufzeiten, als auch für Monate, Wochen oder Tage gestaltet werden. Der Aufwand besteht lediglich in der jeweilig neuen Konfiguration. Also wieder ein Thema für einen automatisierten Prozess.
Erlangt ein Kunde nach einiger Zeit ein Gesamtvolumen von mehr als 4-5 TB, so rechnet es sich, ihm einen eigenen, dedizierten Storagefiler zur Verfügung zu stellen. Voraussetzung ist hier i.d.R eine Laufzeit von mindestens 3 Jahren – eine gute Kundenbindungsmaßnahme.
Eine Anmerkung möchte ich hier noch zu den SSD Platten machen. Diese IO „Monster“ werden heute immer mehr in Servern verbaut. Oft merken Admins erst nach dem Wechsel auf SSDs, wo der Flaschenhals Ihrer Datenbankserver war. Will ein Kunde, der heute gute Erfahrungen mit Datenbankservern mit internen SSDs hat, auf eine VM Umgebung wechseln, so sollte er sich von den internen Platten verabschieden. Virtualisierung und in die Server eingebauter Storage gehören nicht zusammen. Fällt ein Server als Hardware in einer VM aus, so regelt die VM das automatisch (vorausgesetzt, richtige Konfiguration und genug Hardware in der Plattform). Nur die dann auch ausfallenden Platten lassen sich nicht so einfach ersetzen. Es gibt zwar Ansätze dafür, aber diese wird niemand einsetzen, dessen gesamtes Geschäftsmodell an der Plattform hängt. Hier muss immer auf externen Storage umgestiegen werden.
Werden die hier geschilderten Fragestellungen gelöst und die Plattform inkl. aller notwendigen Prozesse betrieben, so kann der nächste Schritt, die Auswahl an managed Services / SaaS, angegangen werden. Die Basis ist gelegt.
Nächste Woche: “Cloud aus Sicht des Kunden”
Tipp: Weitere Artikel zum Thema Cloud Computing gibt es in unserem Special
Zur Person
Stefan Ruehl ist seit fast 20 Jahren im IT-Sales für verschiedene Carrier tätig und hat in dieser Zeit einige der bedeutendsten Web 2.0-Portale in Deutschland beraten und begleitet. In den vergangenen Jahren hat er viele Gespräche mit CIOs, CTOs und CEOs zum Thema Cloud Computing und dessen Vorteile und Risiken geführt. In diesen Gesprächen zeigte sich immer deutlicher, dass die große Herausforderung im Cloud Computing weniger technische, rechtliche oder kaufmännische sind, sondern vielmehr die Vernetzung und Gestaltung von Unternehmensprozessen mit der „Produktion“ und die Annahme neuer Rollensituationen der Mitarbeiter – also eine Top Management-Aufgabe.
Aktuelle Stellenangebote
Alle